A few weeks ago, CEISMIC Digital Content Analyst Lucy-Jane Walsh attended the first day of the Kiwi PyCon Conference. This year the conference was held at the University of Canterbury with Catalyst IT as a Platinum Sponsor. Lucy-Jane discusses her experiences below:
Being a little late to the game, I was only able to attend the first day of Kiwi PyCon, a day mostly consisting of sprints and tutorials, with the usual format of talks left to the Saturday and Sunday. This suited me well – as a bit of a Python fanatic, I was itching to sit down and write some code, to learn new tricks, and perfect my old ones.
To put things in context, I learnt to code with Python, transferring from Javascript after several muddled attempts. After Javascript, Python seemed like a dream: no clumps of brackets and semi-colons, no need to define the conditions of a loop. What I like about Python is that it emphasizes code readability – indentation is used instead of curly brackets, and English words instead of punctuation. As summarized by the principals laid out in PEP (The Zen of Python): ‘beautiful is better than ugly’ and ‘simple is better than complex’.
My favourite tutorial was with Yuriy Ackermann, system administrator at Mount Maunganui College and JS Game developer at SLSNZ. Ackermann taught us how to scrape the web using Python, leading us through a script he had written to gather information about games on the digital game store, Steam. He broke the problem into three key steps – connecting, parsing, and parallelising – explaining the reasons each step were necessary and the libraries and tools he used to do them. I have summarised each steps below:
Connect
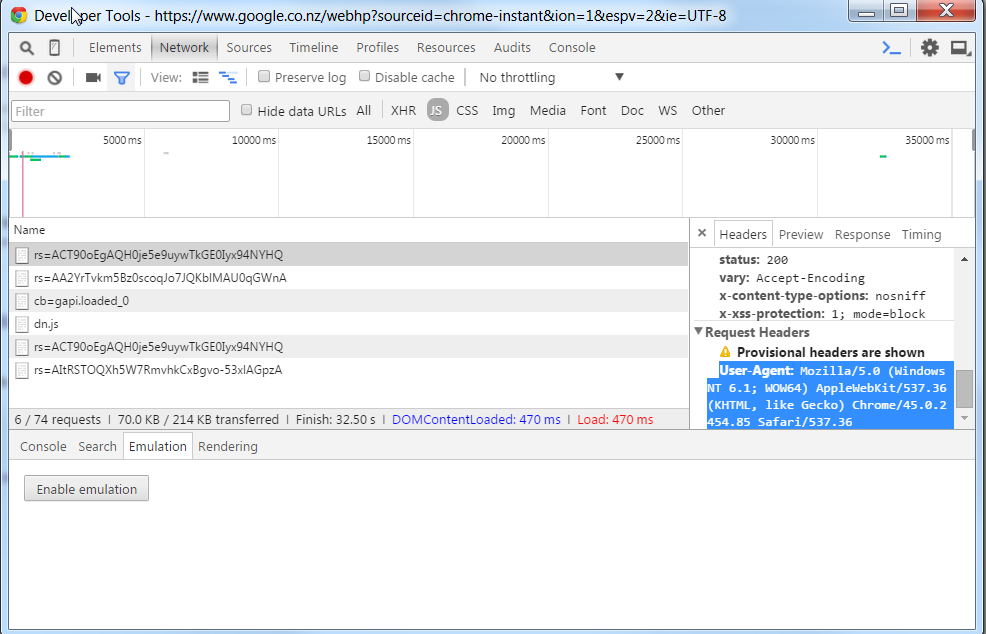
Ackermann used the urllib library to handle urls in Python. Using url.request (in Python3), he showed us how to open a url and decode and read the contents. He also showed us a cool trick for convincing google that you are not a robot. This is necessary for sites like google who reject requests made from outside a browser (encouraging developers to use their API instead). One way to get around this is to place a ‘user-agent’ in the header of the request which reflects browser behaviour. The value for the User-Agent can be found in the develop tools in your browser when you load a url (under the network tab):
Parse
Once the html content has been retrieved, the next step is to parse it. This means finding the parts of a string (in this case a string of html) that we are interested in and organising them into a useful structure. Ackermann used BeautifulSoup4 for this step of the scraping – a Python library built for pulling data out of HTML and XML pages. In particular, the .find() and .find_all() methods are incredible useful, the first allowing you to retrieve the first instance of a tag, and the second retrieving every instance of a tag and storing it in a list.
Ackermann used both of these methods to create a function for parsing urls from Stream. This function takes a string, such as the html from the url of one of stream’s games, and finds the name, price, currency, tags, and rating for that game. He also added some error exception to deal with 404s, timeouts, and pages not have price, tags, and names, and to clean up the data.
Parallelising
Once we had a script that could parse data for one of Steam games, it was time to run it across all of the games. The simplest way of achieving this would be to write a for-loop, but this would require a lot of requests (around 100,000) and a lot of time (7 hours at 250ms per request). On top of this, most websites check logs and will ban IPs that make too many requests. Ackermann’s solution was to move to a parallel process.
This part was somewhat harder for me to understand, having never tried parallel computing myself, and unfortunately we ran out of time. Basically Ackermann set up a server and created a bunch of online virtual machines (VMs). He got the server to send unique urls from Steam to the VMs and set them to retrieving and parsing the information. The VMs would then send it back to his server through a post request. This allowed him to run 100s of requests at once, cutting the time from hours to minutes.
For a step by step guide to this tutorial, check out Ackerman’s slides.
A huge thanks to Catalyst for sponsoring this year’s Kiwi PyCon. I really enjoyed the tutorials and meeting all the other python fans and developers. I hope next year I can attend again and get to hear the talks this time.